假設你已經將你的演算法進行了優化,但是這時發現,這一項演算法工作還是需要花到非常多的時間處理,那要怎麼辦呢 ?
假設你所在的機器是多核心 CPU,那這時的確是有解,那就是本篇文章的主題 :
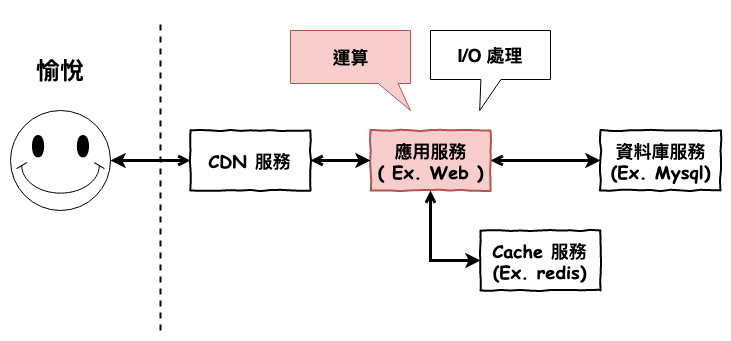
開啟 Process 或 Thread 來幫忙進行運算。
本篇文章就分為以下三個章節:
在實際上理解如何開啟 process 或 thread 前,咱們先從最基本的東西說起。
何謂 process ? 何謂 thread 呢 ?
首先咱們先來看看 process,基本上在你的電腦中每一個應用 ( ex. line、chrome ) 都是至少是一個 process,然後比較重要的一點在於 :
對作業系統來說,它是資源分配的最小單位,並且同時是個『操作單位』
在 linux 系統上,一個 process 的建立過程如下圖 1 所示 :
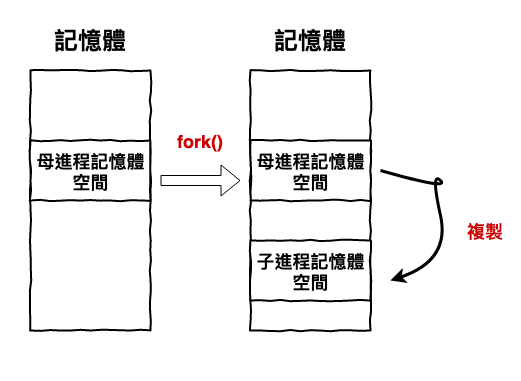
圖 1 : 作業系統建立進程的概念圖
而上面說的資源分配就是指上面步驟 2 分配記憶體空間。然後這個子進程之後工作時,需用到的記憶體,就是那從那一堆子進程記憶體空間來分配。
~ 小備註 ~
在 linux 中不是只有 fork 可以建立一個 process,還有所謂的 vfork 與 clone 這兩種,感興趣的可以去理解一下這幾個差別。這裡就只是淺淺的談談。
然後接下來咱們來看一下,process 在處理工作時,以作業系統的角度來看,它是如何的運作。
咱們假設運行在以下的機器設備上 :
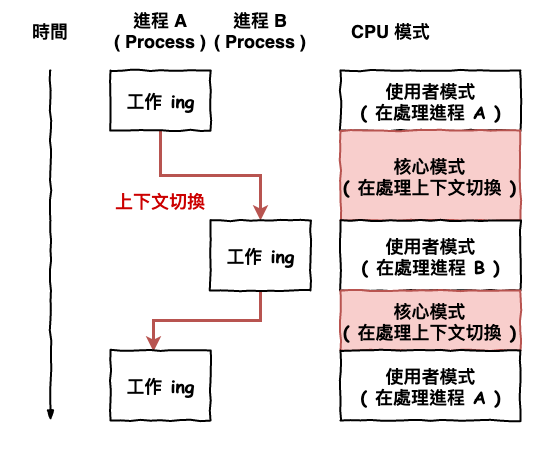
圖 2 : 作業系統工作原理
那基本上它運行的過程會如上圖 2 所示,一下 A process、一下 B process,因為只有一個 cpu,然後每一次要轉換工作時,都需要進行所謂的『 上下文切換 ( context switch ) 』,它是由作業系統的核心 ( kerneal ) 來處理這工作。
上下文切換這個工作基本上,就是將正在處理進程 A 的資訊記錄起來,然後再讀取進程 B 之前做到那裡資訊,這樣才能在重新開始進行進程 B 的工作。
~ 小知識 ~
正常情況下,邏輯 cpu = 物理 cpu 個數 X cpu 核數 ( 先別管超線程 )。然後有幾個邏輯 cpu 就代表『 同一個 』時間可以開幾條生產線來工作。
每一個 process 所能分配到 cpu 的時間片段基本都相同,不過也是可以使用 nice 這種作業系統提供的方法來調整進程的優先權,也就是讓某一個進程比較容易被分配到 cpu 來進行工作。
在來說說這個睡著這個,咱們在寫程式碼不是有時會執行 sleep 還啥的嗎,這就是主動睡,而被動通常是出了什麼事,例如硬體或軟體怎麼了,作業系統強制中斷。
然後另一個東西是 system call。它是什麼呢 ?
這就要來理解一些作業系統,下面這張圖代表這,當在一個 process 裡面,有段程式碼,需要執行網路存取,那它的運行流程就如下 :
其中 3 至 4 的操作就是謂的的 system call。
所以假設發出來一個 http 請求,那會如下圖 3 那樣運行 :
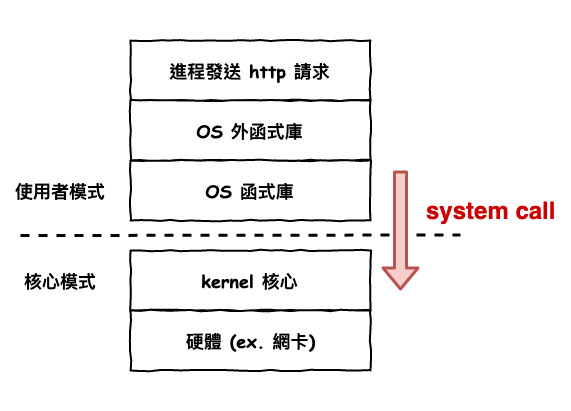
圖 3 : 一個請求的操作流程
這裡簡單說明一下,上下文切換事實上分的很細,如果某個 system call 就只是轉成 kernel 來讓他處理事情的,那這叫特權上下文切換,而如果某個 system call 是要傳送資料這種,那就會進行所謂的進程的上下文切換,就是將 cpu 資源分給其它 process,然後圖 2 的是所謂的『進程的上下文切換』。
~ 小備註 ~
像咱們常常處理的 mysql 操作或 http 請求,底層都是有使用 system call 來去操作網路下的動作,因此在『 某一些情況下 』,它會頻繁的觸發上下文切換,這個在說到 I/O 的文章是會詳談。
在說明完進程 process 以後,接下來我們來說說線程 thread。
它的定義如下 :
對作業系統來說,它是最小的操作單位,且它包含在 process 中。
也就是說,作業系統可以分配 cpu 直接給 thread 來進行工作,然後在同一個 process 中的 thread 都可以共享 process 的記憶體空間。
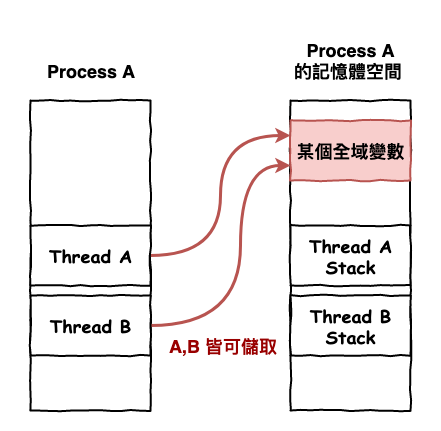
圖 4 : thread 在 process 中的概念
進程 process 與線程 thread 它們都是 cpu 分配的單位,但是為什麼有了 process 還會有 thread 呢 ?
因為 process 太肥了
上面有提到每當 CPU 要從一個進程分配給另一個進程時,需要進行所謂的『上下文切換』,而這個切換所需要做的事情就是將進程資訊記錄起來,而問題就出在進程的上下文切換很耗資源,則也是為什麼會誕生一個,較小的執行單位,因為就可以使切換時所需要記錄的東西就變小囉。
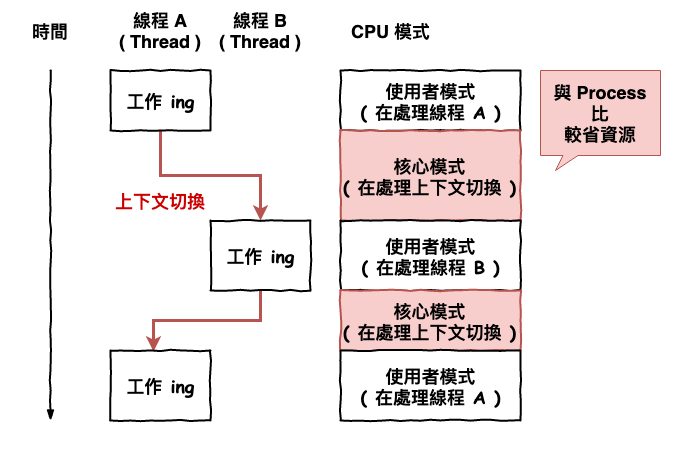
圖 5 : thread 的運行模式
在上面理解完 process 與 thread 的概念以下,接下來我們來說明為什麼開啟它們可以來加速運算,並且進行簡單的示範。
要能加速基本要有以下幾個假設情況下 :
首先是一個,要能開啟進程來加速運算第一個條件是有多個邏輯 cpu,上述在說明時有說過,一個進程或線程同一個時間只能有一個邏輯 cpu 來進行運算。
也就是說,當你只有一個邏輯 cpu 時,這也代表你『 不可能同一時間,處理兩件事情 』,它會如下圖 6 所示來處理任務。
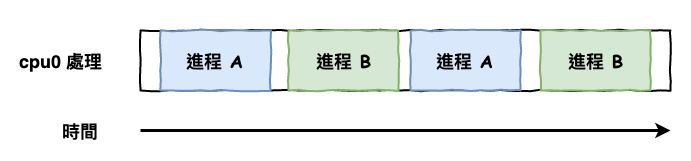
圖 6 : 只有一個 cpu 時的運算情況
而當你有 2 個以上的邏輯 cpu 時才能『 同時間 』處理兩個任務,如下圖 7 所示。
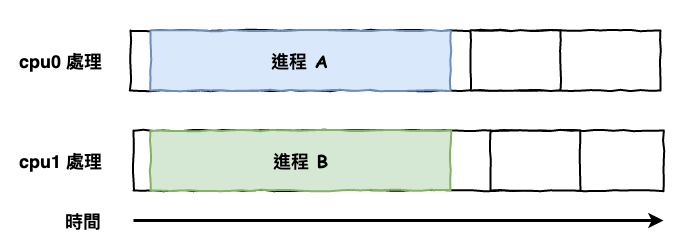
圖 7 : 有多個 cpu 時的運算情況
而第二點那就不用說了,如果你的任務不能拆分,那就沒有必要開另一個進程來處理了。
~ 小知識 ~
將一個大問題拆成小問題,是一個並行工作最重要的地方,這個在演算法中也有很多這種類型的題目,有興趣的人可以去研究一下。
Divide-and-conquer Algorithm
順到說一下 DP 類型也算。
~ 小提醒 ~
大部份的語言都可以開多個 thread 來進行並行運算,但是要注意有一些語言不太行,例如 python (cpyton),主要的原因在於有 GIT ( Global Interpreter Lock ) 這東西在,有興趣的友人可以用這個關鍵字去查查。
接下來我們將使用 nodejs 來寫個簡單的範例。例範內容如下:
範例 :
給定一串數組陣列,計算出陣列所有加總後的數字
這個範例非常的簡單,並且也是很典型的 cpu 運算,然後這裡我們將要模擬開啟二個 thread 來計算運算,然後在分別將結果加總起來,就是答案。
下面這段是主程式碼。
const { Worker } = require('worker_threads')
// 這一段建立 thread,並且將 workerData 丟給 thread。
function runService(workerData) {
return new Promise((resolve, reject) => {
const worker = new Worker('./worker.js', { workerData });
// 監聽有沒有資料從 thread 傳回來。
worker.on('message', resolve);
})
}
// 這裡建立兩個 thread 來並行計算 nums 數組。
// 第一個 thread 負責計算第 0 至 4 個
// 第二個 thread 負責計算第 5 至 8 個
async function run() {
const nums = [1,3,4,7,8,9,19,11,12];
const result = await Promise.all([
runService({
nums,
start: 0,
end: 4
}),
runService({
nums,
start: 5,
end: 8
})
])
return result[0] + result[1];
}
(async () => {
const res = await run();
console.log(res);
})()
而這一段是負責運算用的 thread 程式碼。
const { workerData, parentPort } = require('worker_threads');
// workerData 為從母進程傳送過來的資料
const nums = workerData.nums;
const start = workerData.start;
const end = workerData.end;
let sum = 0;
for (let i=start; i <= end; i++){
sum += nums[i];
}
// 將運算結果回傳至母進程。
parentPort.postMessage(sum);
上面這些就是簡單的開啟二個 thread 來分別進行計算,然後在將結果返回。
以這個問題來看是可以不用這方法,不過這只是範例,別太在意。
~ 小知識 ~
nodejs 忘了在幾版以後就有 thread 可以使用了,在比較舊以前的 nodejs 世界只能開 process。然後這裡我用的是 nodejs v12.10.0,不過注意一下它的狀態還是『 Stability: 1 - Experimental 』。
上面有提到,thread 是可以共享 process 的記憶體空間,因此可以所有在裡面的 thread 都可以讀取那個共享的變數,而這在某些情況下,就會發生問題。
最有名的例子下面這段 java 程式碼。
public class System {
private int count;
public int getCount(){
return count++;
}
}
這一段程式碼有什麼問題呢 ? 假設咱們開 2 個 thread 來執行 getCount,就可能會發生如下圖的問題,明明執行兩次 count++ 但是最後結果卻只有一次。
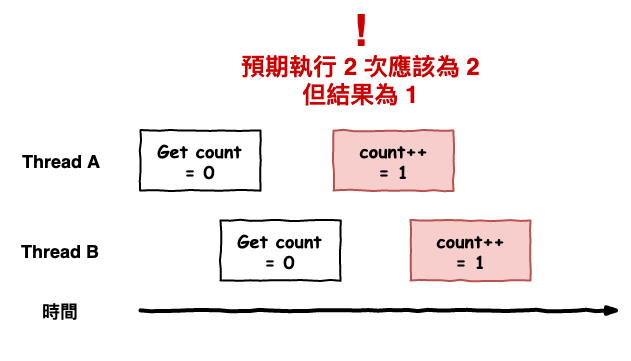
圖 8 : 並行的問題。
~ 小備註 ~
這裡就是咱們第一個碰到的一致性問題,後面還有一堆這種問題,慢慢看。
在 java 最多人使用的解法就是『 加鎖 』,如下程式碼,它會將這個方法所屬物件給鎖定起來,也就是說在同一個時間,只能一個 thread 來執行這一段。
public synchronized int getCount() {
return count++;
}
而當使用這個方法時,事實上運行就變成下面這張圖的感覺,因此這也代表,性能被限制住了。
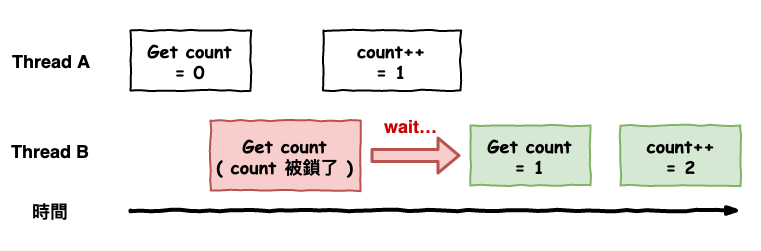
圖 9 : 加鎖後的運行圖
有寫過 golang 的友人們應該是有看過下面這一句話。
Do not communicate by sharing memory; instead, share memory by communicating.
這句話是說,不要使用共享記憶體來進行溝通,而是使用溝通來分享資料。上述 nodejs 的範例就是屬於這一種思想方案。
~ 小備註 ~
上網仔細查了以後,基本上發現以這種思想所產生的模式事實上有兩種『 Actor 』與『 CSP 』。像 Java/Scala 的 Akka 庫就是 Actor 實現,而 golang 則是 CSP 的實現,之後會開篇文章來詳細說明。
本篇文章中咱們學習到了應用層的一項運算加速的方法,並行運算,不過要使用這個東西有兩個條件 :
同時咱們學詳細的學習了 process 與 thread 這兩個在作業系統中的運算單位。理解它是如何運作與產生,同時在這裡也碰到第一個一致性問題,這個問題只要是在性能與可用這條路上會形影不離的追隨這咱們的。

